

Preparation &
Proper Installation
0- Best Practices & Ethics
Here are a few conventions that will certainly save you a lot of moral, financial and social trouble:
A) Disclose your utilization of AI.
Before selling or engaging in any sort of trade, EXPLICITLY disclose and inform the buyer that the visuals or graphics you’re going to provide are entirely or partially AI-generated, well before any deal or promise of payment is made.
Openly acknowledging the AI-generated nature of your work will uphold your integrity and remove the likelihood of clients being misled or deceived.
Upfront disclosure is not only a courtesy to your clients but also a safeguard for your reputation and the integrity of the AI community.
B) Be responsible with vocabulary.
Try to not use the words “art” or “create” when referring to the images, visuals or graphics that Stable Diffusion & other Generative AIs generate.
Utilizing the terms “generated” “images“, “visuals” or “graphics” will still describe the work, without potentially misleading or implying human-like creativity, effort of manual creation, or complex creative intention.
Similar to point A, this will significantly help your integrity, while consequently allowing most to feel more comfortable being involved with you and your works.
C) Credit the original artist.
When the image you’ve generated are deliberately styled after an artist’s body of work, credit the artist.
A very simple attribution can not only save you a lot of trouble, but even give the original artist some exposure!
1- Prepare Yourself – (optional)
We strongly recommend increasing your PageFile if you’re using Windows, and SWAP if you’re using Linux;
by adding “fake memory”, you will allow a lot more flexibility for your system, and potentially prevent many strange issues.
Here’s a really quick guide on how to do it on Windows:

We also recommend rebooting your system from time to time.
There are many users who leave their system on for a very long time; memory leak or misallocation (although uncommon) can happen and stack up over time, causing a variety of enigmatic issues.
2- Install Stability Matrix
Grab a fresh release from https://github.com/LykosAI/StabilityMatrix/releases

After putting the file in a neat and proper location (ideally SSD), extract it,
Keep in mind, given how Python dependencies are coded, you will not be able to move the installation freely, so choose the location wisely.

Run it, and select portable mode.
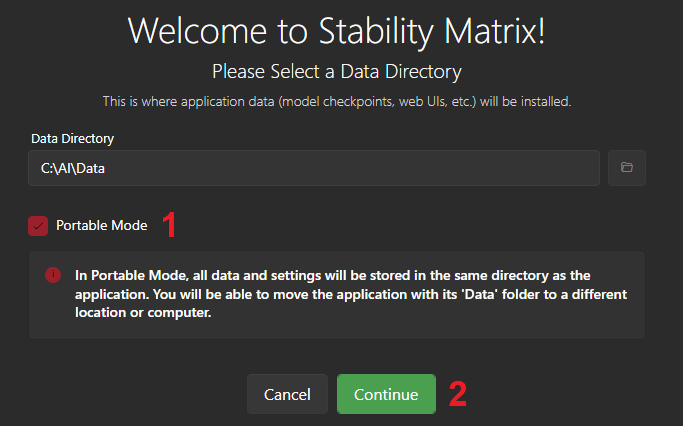
3- Install an Interface Package
There are 5 great options, sorted by our recommendation:
A) WebUI by AUTOMATIC1111 is the default option, an often-updated forerunner among interfaces.
B) Fooocus, similar to the WebUI, is a solid pick with DirectML support (for windows AMD users).
C) ComfyUI is an advanced option that will give you the most control over the generations, it also enables Stability Matrix itself to act as interface.
D) VoltaML has a solid interface, with the additional option of being configured to generate incredibly fast.
E) InvokeAI should be picked if you need the fancy inpainting, outpainting and editing tools it comes with.
Remember that you must select an interface with DirectML support if you’re using windows with an AMD graphics card.
You would then need to add “--use-directml” to the extra launch options to utilize your AMD graphics card in windows.
If your graphics card’s Vram is 4GB or less, enable “--lowvram” (or add it to extra launch options).
On Nvidia’s Pascal series (GTX 1070, 1660 super, Titan, etc), we recommend you enable “--no-half” for better performance.
4- Add Models
Grab some up-to-date models and put them in <Stability Matrix Location> /Data/Models/StableDiffusion/
Here are 3 Stable Diffusion Versions along with the respective models we strongly recommend:
A) DreamShaper SD 1.5
SD 1.5; Minimum 4GB Vram, 16GB Ram.
https://civitai.com/models/4384/dreamshaper
Pretty much the best option all-around.
B) DreamShaper SDXL 1.0 Turbo
SD XL (Turbo); Minimum 8GB Vram, 32GB Ram.
https://civitai.com/models/112902/dreamshaper-xl
Extremely capable, but very demanding for complex operations.
C) Illuminati SD 2.1 (768)
SD 2.1; Minimum 6GB Vram, 16GB Ram.
https://civitai.com/models/11193/illuminati-diffusion-v11
A newer model, yet overshadowed by the well-supported SD 1.5.
5- Make a Backup – (optional)
Go to Stability Matrix directory, archive the entire folder containing everything into a zip file, and keep it as backup.
Permanent Stable Diffusion errors and corruptions are rare, but can still happen.
You should rely LESS on re-downloading, as there are many dependencies involved, and each one of their fates is not set in stone.
Keep in mind, given how Python dependencies are coded, you will not be able to run this backup in any location other than the place you originally backed it up from.
6- Update Carefully – (optional)
Make sure you have a stable internet connection and a backup before you update an interface package, or even just Stability Matrix.
Interruptions during the download of an interface often cause complete corruption, and this is the case with all of them.
If you’d like to not be tempted to update, you can disable it in Settings – Updates – Disable Update Notifications
How to Use & Prompt
Stable Diffusion
Prompt
Your prompt might have:
- Topic: 2girls, nuke, 1boy, car, chicken, house
- State: standing, sitting, eating, corroded
- Cinematography: long shot, full body, close-up, cinematic lighting,
- Secondary Topic: backpack, dress, necklace, teeth, horns, tail
- Environment: forest, street, village, urban, cyber city,
- Quality Descriptors: best quality, masterpiece, absurdres, highres, ultra-detailed, detailed,
- Attributes: pastel, happy, looking to side, shiny, red,
- Stylization: realistic, pixar, illustration, monochrome, sketch, anime, cartoon, by {famous artist name},
For the purpose of this guide, we’ll be trying to generate an image of a schoolgirl with white hair, wearing a black uniform and a red backpack, in a black and white classroom.
Choosing Prompt Keywords / Tokens
The easiest way to come up with tokens is to think what tags your vision would have in a booru such as https://safebooru.org/
Alternatively, ask yourself, what tags would people enter the booru search engine to find your vision?

Order of Tokens
With the way Stable Diffusion processes your prompt, the order of the tokens in your prompt can affect the final output.
The foremost tokens are more likely to be the primary objective of the output.

Tags vs Sentence
We advise a fragmented Prompt such as: “1girl, schoolgirl, white uniform“ rather than a full sentence like: “a schoolgirl in white uniform“

Even though they give very similar results with very small prompts, long sentence-type prompts are prone to be partially dismissed or get interrupted by unintended filler words.
Having to rewrite your entire sentence because you want to change a detail, or even having to worry about articulation, can be avoided altogether!
Fragmented prompts not only give you more control since they are more modular and can be edited a lot more efficiently, but they’re also less likely to be ignored.
Topics & Attributes
It is important to define the scope of a topic and its attributes, because otherwise they will bleed into one another.
If you mention multiple topics and attributes without defining their boundaries, they might merge into a single one, or more commonly, be partially ignored.
1girl, schoolgirl, black, uniform, red, backpack, white, hair, greyscale, classroom, background.

Different primary topics should be separated by dots, while a topic and its attributes should be unified into a single token, or at least be grouped in parentheses / brackets.
This not only makes it a lot more readable, but it will also prevent accidents while you edit the prompt.
Try to keep your tokens as bite-sized and descriptive as possible;
if there are multiple attributes for a topic, we recommend separating them for more emphasis, for example, “red backpack, leather backpack“, instead of “red leather backpack“
1girl, schoolgirl, black uniform, red backpack, white hair. greyscale classroom.

Token Weight
The default weight of a token is 1 but you can change this value by adding a : followed by a number. e.g. 1girl:2
For example, in the prompt “1girl:2, schoolgirl, black uniform,”, the 1girl tag has twice the weight as usual, which means the result will prioritize its depiction.
In WebUI and Invoke, you can also add the weight indicator after brackets or parentheses as well, such as “(1girl, schoolgirl):1.5, black uniform.”.
Generally, tokens with more weight, or in parentheses, are more likely to be the main objective of the generation.
Note that parentheses each apply a 1.05 multiplier to weight, while brackets divide it by 1.05 each.
1girl, schoolgirl, black uniform, (red:2 backpack), white hair. greyscale classroom.

Negative Prompt
Even though the same grammar mentioned above applies to them, negative prompts act as the complete opposite of positive prompts.
They can be particularly useful for defining styles, for instance, if you’re aiming for a classic anime look, you might use negative prompts like “3D” and “realistic” to steer the AI away from those styles.
And most importantly, they can be used to reduce or remove an unintended generation;
if you keep getting a topic or attribute that you didn’t want, you should first re-check your positive prompt, and if there’s no fault in it, add the unintended token to your negative prompt.
1girl, schoolgirl, black uniform, (red:2 backpack), white hair. greyscale classroom. black backpack. colorful classroom.

Samplers
Stable Diffusion essentially generates visual noise, then sorts it according to patterns that it has extracted from analyzing images and artworks.
Samplers are basically the way Stable Diffusion sorts the visual noise into comprehensive images.
We could go over them here, but fortunately Félix Sanz has already made a wonderful blog post covering most samplers with side by side images.
Check it out: https://www.felixsanz.dev/articles/complete-guide-to-samplers-in-stable-diffusion
When downloading a model, you should read through the description to see what sampler the creator of the model recommends.
Sampling Steps
Sampling steps are the number of iterations Stable Diffusion must go through, in order to generate a recognizable image out of random noise.
While increasing the number of steps does improve the clarity and logic of generation, it has a very sharp diminishing return curve, and rather obviously, more steps will result in longer generation times.
We generally recommend 13~18 for simple generations (like a portrait), and 26~32 for more complicated compositions.
CFG Scale
To put it concisely, the higher your Context-Free Grammar Scale is set, the more faithfully Stable Diffusion will follow your prompt.
We recommended a CFG of 3~5 if don’t want anything specific, whereas a scale of 6~9 is regarded as the default or normal.
We generally recommend against going higher than 9, unless Stable Diffusion is for some reason ignoring part of your well-written prompt.
Resolution
Higher resolutions generally yield more detailed and visually appealing images, but when the resolution is too high or too low, the generated images lack detail and appear smudged.
Know that different types of images are naturally in different orientations, for example, character portraits are often meant to be generated in a vertical orientation, while it should be horizontal for sceneries.
Start from 512 by 512 on Stable Diffusion version 1.5, and increase either axis to 768 or 1024 to get the type of image you desire.
Keep in mind that for Stable Diffusion 2.1 (768), your resolution should usually start at 768 by 768.
Complementary Knowledge
See supported artist styles and their effect on generations.
See supported modifiers and their effect on generations.
See WebUI’s official wiki for more technical details.
Final Notes
Disclaimer for Clients
We do NOT utilize AI in creation of any of our artworks and assets.
To reiterate, none of our deliveries are AI-assisted.
If you’re a past, current or prospective client, rest assured that your request is completed 100% by hand.
We think it’s important for studios and artists to remain up to date with the capabilities of AI as it progresses, regardless of their stance.
Troubleshooting Issues
You can join the creators of Stability Matrix (Lykos AI) or Morrow Shore on Discord:
Tipping & Support
Did you find this guide useful?
Even very small tips will greatly encourage us to create better guides and provide better support!



Leave a Reply